The Dynamic Context Problem:
How Carta’s internal AI agents save thousands of hours of back-and-forth work
“We focused on workflows where human judgement was essential but inefficient, situations where delays or inconsistencies in judgement degraded client experience. AI shines in scaling judgement, especially when it can draw from rich context and act autonomously.”
Carta built dynamic AI agents to solve complex accounting problems. The most impactful use case turned an 11-minute task into one that’s completed in seconds — normally, there are 20,000 to 25,000 of these tasks per month that need to be reconciled by Carta’s internal teams. That’s a savings of over 3,500 hours per month. This enables a faster, more scalable, differentiated service experience for internal teams and their clients.
To learn more about it, we sat down with Tikmani and Vrushali Paunikar, Carta’s CPO, to understand how a small AI working group solved one of Carta’s most pressing problems.

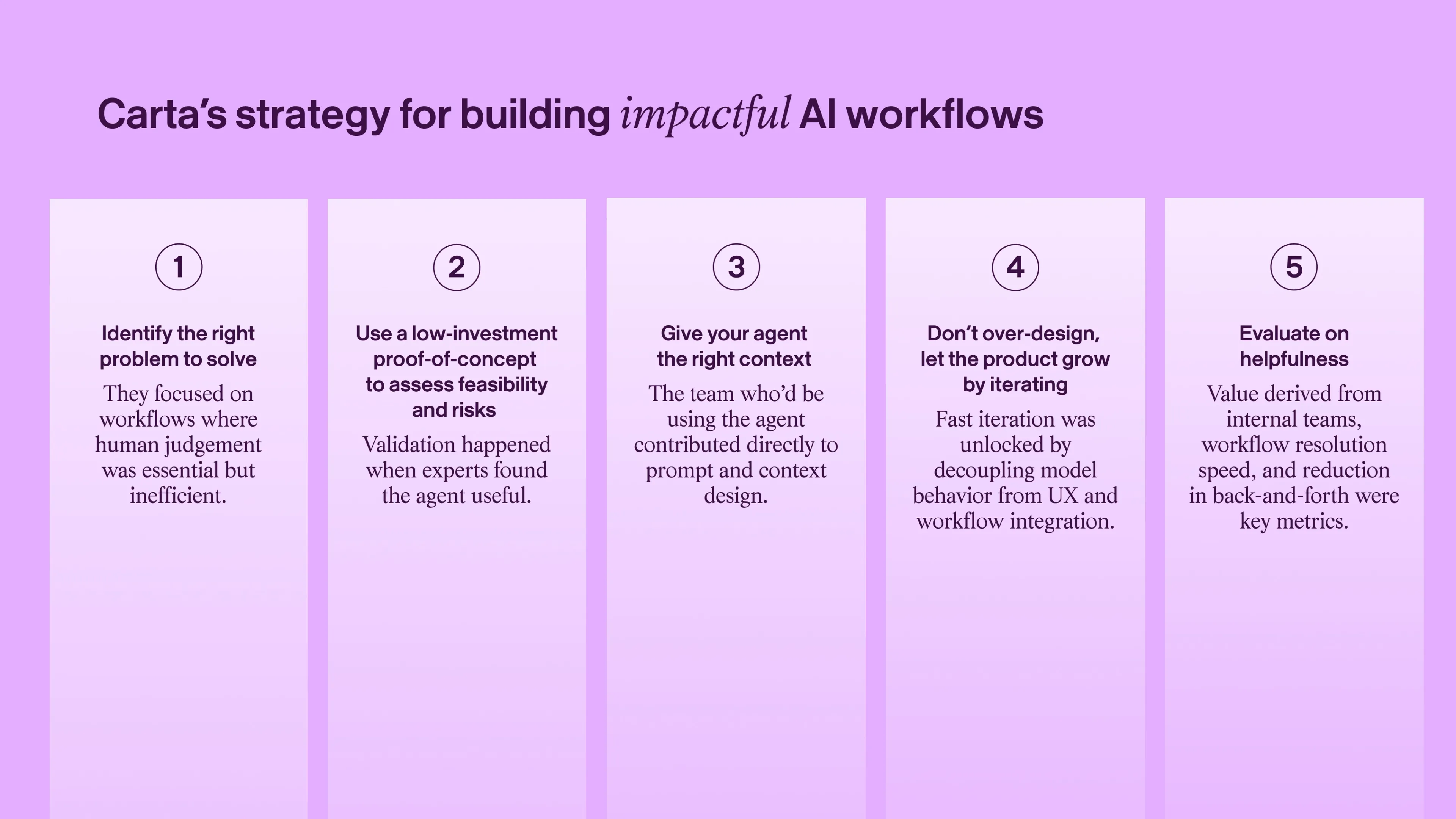
Identify the right problem for AI to solve
Carta operates as a system of record for private capital, serving two sides of the market. Its core business is equity management software, helping over 50% of all venture-backed startups and their employees manage things like stock options, investor stakes and equity dilution.
The other side of its business is materially different: fund administration. It’s service-based, helping investors handle complex accounting, reporting and compliance work. Each fund operates on a different set of principles set forth in legal documents (like a Limited Partner Agreement) that live outside of Carta.
“The most valuable thing we can do with AI is extract the source of truth from these documents and use it to power our workflows and dashboards,” says Paunikar. “The focus of our LLM efforts and innovations is being able to categorize and extract data, and populate our system of record based on those documents.”
This side of the org has 600 employees serving 2,500 customers. It’s operationally intensive, requires deep domain expertise and involves repetitive but judgement-heavy tasks — doable when someone has three to four clients, harder when they have six and much harder when they have 20. Some of Carta’s teams have 40-50 clients.
Scaling this business is bottlenecked by context-gathering — which Paunikar sees as an industrial engineering problem.
There’s a wide set of tasks that service team members can do for clients, and when a problem arises, they must figure out what action to take to resolve the problem. Without context, it takes a lot of time to figure out what’s happening, what to do and how to fix it.
We worked closely with domain experts and engineers to pinpoint judgement-heavy workflows, ones where agents could understand the task, build relevant context, and suggest or complete next steps.
The first was an internal pulse check agent. There are a series of pulse checks in Carta’s fund accounting products that flag errors for fund accountants to resolve. For example, if there are differences in the balance sheet and income statement, the agent will trigger a failed pulse check, diagnose what’s happening, flag it to the correct team and provide a set of detailed next steps about how to resolve it.
Once it was demonstrated that autonomous agents could navigate one complex service workflow, the team expanded to another pressing area in fund admin: cash reconciliation (comparing a fund’s external bank feed to Carta’s internal general ledger and resolving any discrepancies).
Start with a focused, low-investment proof-of concept
The goal of the PoC was to test whether the cash reconciliation agent could reliably handle the task. Given an unreconciled transaction, could the agent gather the right context, reason through the numerous paths a fund admin would follow and produce actionable next steps, or even, complete the reconciliation?
Traditionally, this process required pulling data from multiple systems, reading through client notes, reviewing historical transactions and applying specific logic from individual firms to book journal entries correctly (the formal accounting record of a financial transaction in a company’s general ledger).
Stay ahead.
Get Applied Intelligence in your inbox.
Getting to resolution often required back-and-forth between fund admin, engineering, and support teams to piece together the full picture and decide the appropriate action. Carta’s agent needed to replicate that entire workflow autonomously, so the team validated and de-risked it based on a set of criteria determined by what the tool’s ideal workflow would be:
- Could the agent retrieve the right context from a single internal tool via an API or database query?
- How should they structure and present agent-generated diagnosis and recommendations to internal teams?
- Do early users find the output useful and accurate enough to act on?
- A stretch goal was deciding if the agent could go beyond a “suggestion” and start completing steps autonomously. What would Carta’s AI products team need to do in other parts of the product to make that possible?
Workflow validation was the tactical part of determining if an agent would be impactful for the fund admin team. Looking toward its build, there were other implementation considerations:
- Build vs. buy — This depends on the problem you’re trying to solve. Carta’s was deeply vertical. “The key lever for agent performance is access to the most relevant, structured context, which is only possible through deep integration with our internal tools and data,” says Tikmani. If an off-the-shelf solution exists, you can use it. “But we didn’t need a finished product, we needed to validate feasibility and iterate quickly. Building in-house gave us that flexibility,” he says. At a high level, the team’s core toolstack was OpenAI models and APIs. For the agents specifically, they added a chat-based interface, pgvector to enable semantic search and vector similarity. They also used existing modular functions and code for API calls and DB queries, which were already part of the toolstack, but repackaged for agent use.
- Building on foundational models vs. fine-tuning — Think about both data and time to launch. “Training our own model would’ve required significant investments with little upside for the types of judgement-based tasks we’re solving,” says Tikmani. “We chose to build on top of foundational models because the quality of performance comes more from the richness of context than from model customization.” And since Carta already had all that context, using it effectively through in-context learning gave them strong results without the overhead of customizing models.
For Tikmani, validation wasn’t just a quantitative metric. He knew it was viable when fund accountants reviewed the agent’s reconciliation decisions and found them accurate, well-reasoned, grounded in the right context and immediately actionable.
We put the product in front of our users and got great feedback early so we could understand what happened and what should’ve happened.
Immediately, it showed great efficiency for both the fund admin team solving the problem and the engineering team helping them do it. That’s the confidence Carta’s AI and leadership teams needed to invest further.
Give the right context for specific tasks and tools
This thing wouldn’t work (or provide any actual value) without the right inputs. To give its agent the context it needed, domain experts diagram a full workflow in Lucidchart, which acts as the source code for the agent’s system prompt. They use an internal prompt generator to convert the Lucidchart into JSON, feeding that into the agent programmatically.
To get context that informed the iterative build process, the AI working group prioritized speed and functionality over UX polish. “It’s more about proving value and scalability of agentic workflows in production environments,” says Tikmani. With that in mind, the team was kept small: three engineers (Thomas Yook, Justin Lin and Titus Peterson), working directly with Henry Ward (CEO) as acting Product Manager and no dedicated designer.
But the core contextual input came from fund admin experts and in this case, Brady Fisher from the solutions team — people who’d actually be using the tool and helped shape it into something useful. “Teams that best understand the domain are contributing directly to prompt and context design, improving velocity and relevance without needing to train models or learn ML,” Tikmani says.
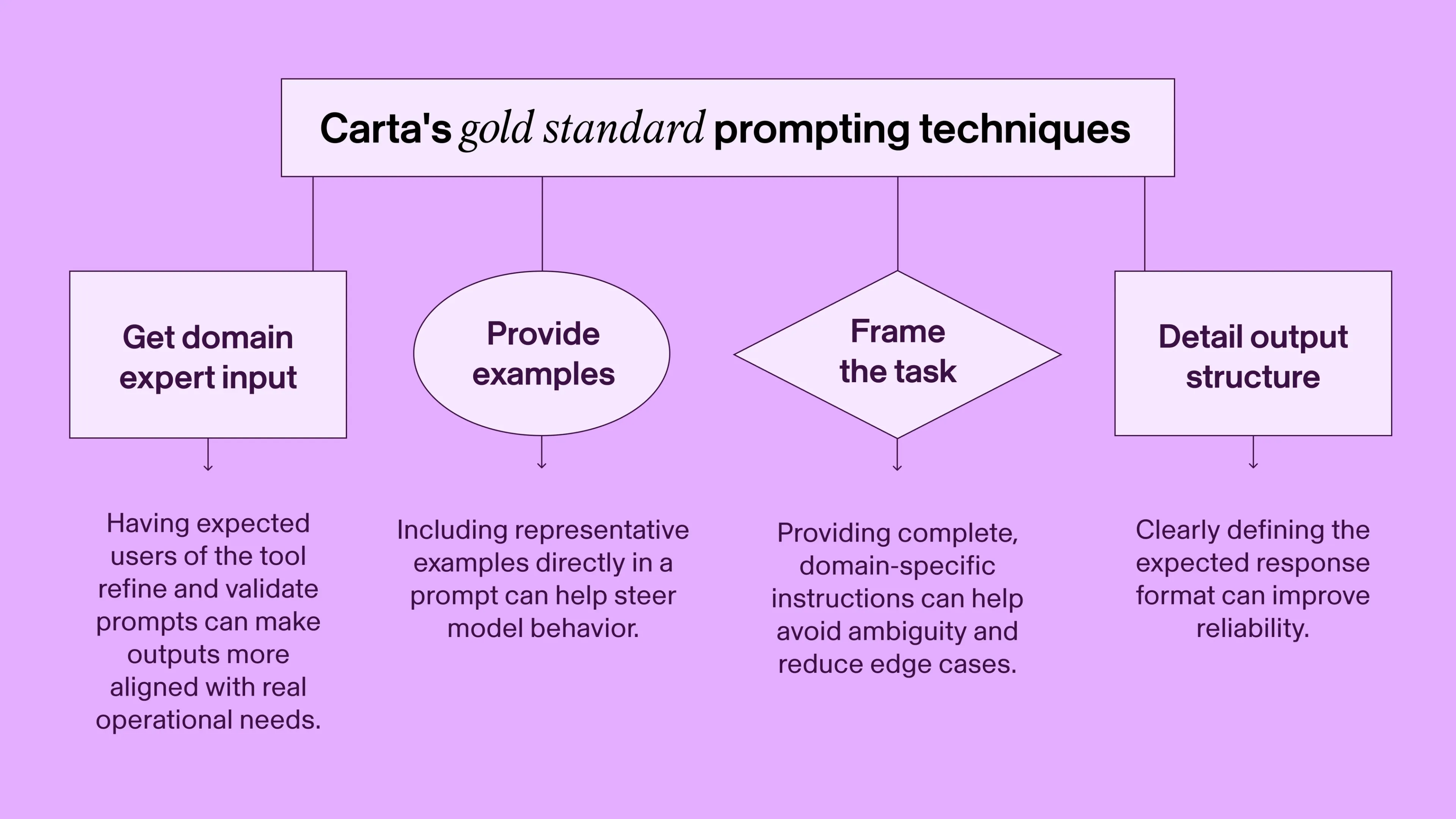
With expert input, they established a set of gold standard prompting techniques relying heavily on in-context learning:
- Provide examples: Including representative examples directly in the prompt helped steer model behavior.
- Expected output structure: Clearly defining the expected response format improved reliability.
- Detailed task framing: Providing complete, domain-specific instructions avoided ambiguity and reduced edge cases.
- Domain expert input: Specific teams (like fund admin and accounting) refined and validated prompts based on how they think about their work. This made the prompts far more aligned with real operational needs.
As with any AI product, the prompt became an essential part of the product’s usability. “Prompting is becoming democratized,” says Tikmani. “People who are closest to the problem and what they’re trying to solve will try to prompt their way to a solution. If the AI can do it, then you just have to give it the right context.”
Don’t design everything up front
When prototyping, the team made a decision to move as quickly as possible: “Unlike traditional software, where performance is largely driven by deterministic logic, AI product performance also depends on model behavior — which is controlled through model choice, instructions and context design. To enable fast iteration, decoupling this layer from the UX and workflow integration is important,” Tikmani says.
Approaching prototyping with this framework, the team could continue evolving the agent’s reasoning and output quality without needing to constantly rebuild the product surface or its backend systems. Instead, they tested model behavior with rough setups and domain expert feedback instead of shipping full features. This separation is what made the rapid process of testing new capabilities possible.
Skip the AI theater.
See what’s already running in production.
“For every failure or inaccuracy by the agent, we asked the cash reconciliation team to walk us through how they would have handled the situation, what steps they would take, which information they would check, and what decisions they would make,” says Tikmani. “We pushed to extract their logic and decision tree, encoding that into the agent.”
As the prompt grew more complex, they moved everything from the decision tree — when to take which step, what to pull, how to decide — into Lucidchart (which was actually Ward’s idea, which was a game-changer for the whole process). This made it easier for business teams to maintain and update agent logic as they identified new mistakes, with the agent pulling the latest decision trees into prompts for its next iteration of the task.
Having the logic mapped out, step by step, made it easier to debug where the agent went off track.
“We’re now adding the ability to re-run the agent from the step where it made a wrong decision, so it can correct its trajectory with targeted feedback, rather than having to start over each time.”
Even though there wasn’t a formal evaluation loop at this point in the product’s infancy, Carta leaned on its internal teams for feedback on both the agent’s workflow and UX layers. One piece of feedback from experts was on the product’s design. It forced Tikmani to change his opinion on something he initially felt strongly about: chatbots.
“From the beginning of this foundational AI era, one of the things I pushed back on was the default impulse to build chatbots,” he says. “Not because chatbots are bad, but because so many were being built without thinking through whether that was actually the right user experience. Over time, I’ve come to see their value, especially during the ideation phase or for internal tools where quick iteration and debugging matter more than UX.”
His coming-around was rooted in the fact that conversational UI enables faster feedback loops and iteration cycles — without needing to lock in final UX or UI decisions. “When you’re just seeing what’s possible, it’s helpful to understand how people are using the product,” says Tikmani. “This approach gave us a flexible surface to test how users interacted with agent reasoning, tool use and recommendations.”
Other key design decisions were:
- Building trust by showing tool usage and intermediate results (which also helped users debug agent behavior).
- Giving context in the form of exposing model reasoning to explain outputs. This also helped differentiate between clearly wrong results and those that were logically sound but not what the user expected.
- Providing controls to users, allowing them to rerun parts of the agent workflow, especially the precomputed context or planned steps which improved flexibility and correct for imperfect inputs.
- Holding off on more rigid UI design so they could stay close to the intelligence layer and learn from real usage.
- Limiting complexity by not allowing users to manually select which tools the agent should use. This would’ve offered more control, but felt like it was undermining the goal of making the agent autonomous.
AI tools are making prototyping fast, easy and cheap. But this capability really unlocks rapid iteration and feedback — which Carta did by continuing to bring experts into the co-development process, making the product better by learning from people executing the workflows the agent would eventually augment.
Evaluate on one thing: Is this helpful to users?
As is the theme, the agent’s evaluation process was driven by usage and real-world feedback from internal experts. “They interact with the agent directly, assess usefulness and surface gaps in accuracy or context,” Tikmani says.
This hands-on loop has been the most valuable signal for iteration. These give us directional indicators on where the agent is driving impact.
The metrics they used to determine adoption were all around frequency and breadth of use, like how often the agent was triggered and across how many workflows. They also looked at:
- Helpfulness ratings from internal teams, often collected directly in the interface or via follow-up.
- Workflow resolution speed, whether that was failed health checks, unreconciled transactions or if other issues were resolved faster.
- Reduction in back-and-forth between teams, which they tracked through fewer escalation or handoffs in the servicing pipeline.
Dogfooding was an essential input into the evaluation process, but it required some pre-work to provide meaningful data — specifically educating the team using the product on which parts of the experience were AI driven vs. explicitly programmed. “With AI products, small prompt or context changes can lead to different outcomes,” says Tikmani. “So we had to reset expectations.”
This feedback was really more about helping the team shape the boundary between automation and human input, and less about identifying specific failures.
Real AI implementation stories.
Straight to your inbox.
As the product’s capabilities mature, Tikmani aims to introduce the structured and systematic eval processes that Carta uses for its more mature external agents:
- Track every step the agent takes, including tool calls, inputs, intermediate results and final outcomes.
- Log and compare human edits to prompts so they can assess system-generated vs. expert-curated inputs, hoping to improve performance.
- Evaluate tool accuracy, step efficiency and resolution outcomes across various paths.
- Capture feedback on helpfulness using both human- and LLM-based reviews to assess response quality.
- Eventually, he also plans to build a baseline test suite to ensure agent reliability as the team updates prompts, swaps models or expands capabilities. The focus here is on supporting iteration while maintaining confidence in performance.
Implementation and impact
Internally, Carta (like many companies) is attempting to stoke as much AI usage as possible. Tikmani credits Carta co-founder and CEO Henry Ward and Dan Fike, Deputy to the CTO, for creating space for experimentation and room to innovate as a large reason for the agent’s build and broad use.
To see if the agent is working, they track usage of core systems like OpenAI to understand adoption patterns and guide investment. “The ML team and engineering leads partner with teams across the org to support adoption through shared infrastructure, education, and direct consulting,” says Tikmani.
To ensure consistency, they’ve published internal strategy docs that outline best practices for AI usage, covering prompting, evaluation and which internal tools to use for which types of problems. This is similar to how Carta standardizes other engineering practices. “We’re still building toward a more mature tooling for prompt versions and evaluation across workflows as adoption scales,” he says.
The projected time savings provided by the agent are impressive — over 3,500 hours per month. But because it’s surfacing important context from across teams that would normally be siloed, it’s increasing the baseline level of knowledge for the people using it.
“Although still in its early stages, Carta’s AI Assistant is demonstrating promising progress,” says John Michael Clarito, who is on the Cash Reconciliation team. “It’s evolving into a valuable learning companion and a quick-access resource for nuanced context, helping enable faster and more informed decision-making.”
Stay ahead
An unfair advantage in your inbox.